AI革命の中で高まるプライバシー保護の重要性
現代社会においてAIや機械学習技術は急速に発展し、私たちの生活のあらゆる場面に浸透しています。医療診断から金融取引、スマートフォンの予測変換に至るまで、機械学習モデルは膨大なデータを基に精度の高い予測や判断を行うようになりました。しかし、こうした技術の進化に伴い、個人情報やプライバシーの保護という大きな課題が浮上しています。
機械学習モデルの精度向上には大量のデータが必要ですが、そのデータには個人の行動パターンや健康情報など、極めて機密性の高い情報が含まれることがあります。世界各国ではEU一般データ保護規則(GDPR)をはじめとするプライバシー保護法が整備され、企業や組織は個人データの取り扱いに厳格な制限を課されるようになりました。
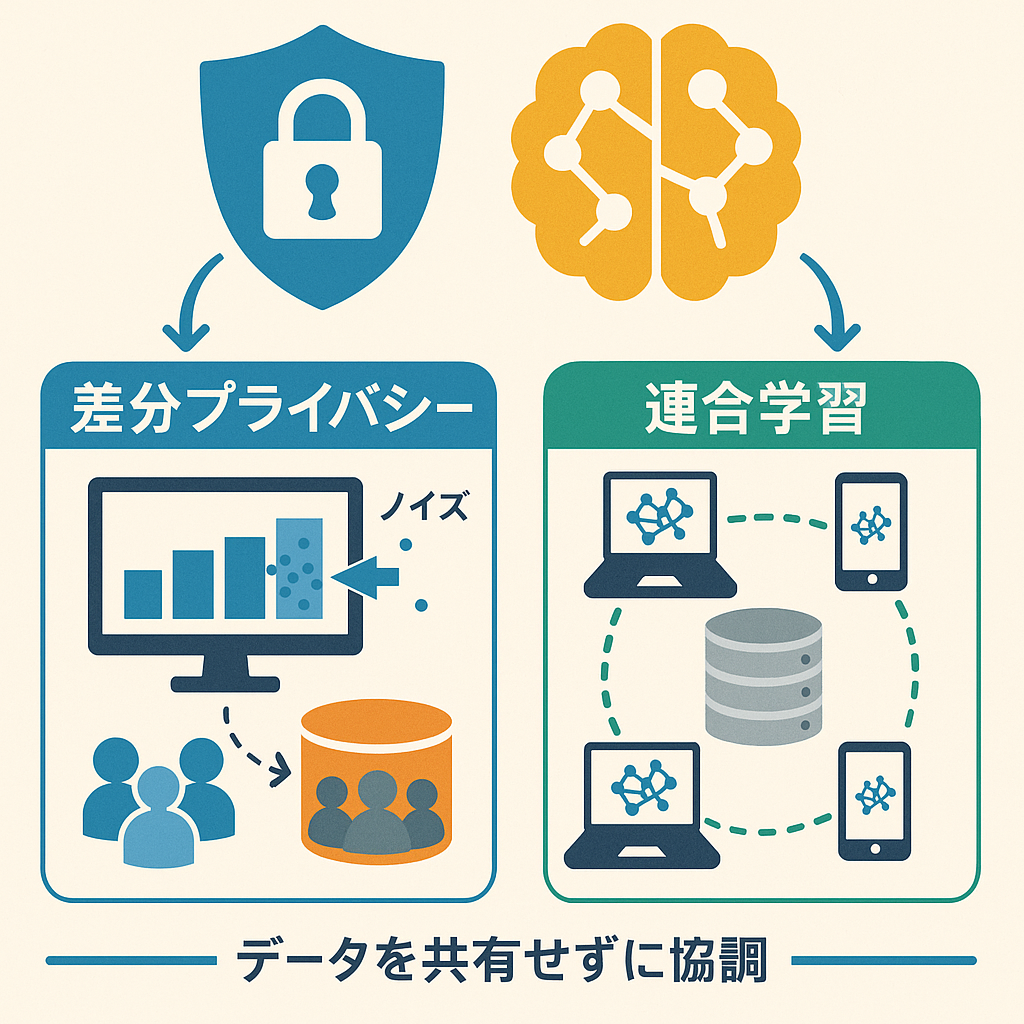
この状況において、「いかにプライバシーを保護しながら高性能な機械学習モデルを構築するか」という問題に対する革新的な解決策として、差分プライバシー(Differential Privacy)と連合学習(Federated Learning)という二つの技術が注目を集めています。
差分プライバシー – データにノイズを加えてプライバシーを守る
差分プライバシーとは
差分プライバシーは、2006年にCynthia Dworkらによって提案された概念で、個人データを統計分析に使用する際、プライバシー保護のための数学的な手法です。この技術の核心は、データセットから得られる統計分析の結果が、ある特定の個人のデータが含まれていても含まれていなくても、ほぼ同じになるようにすることにあります。
差分プライバシーの仕組み
差分プライバシーでは、データに意図的に「ノイズ」を加えることで個人情報を保護します。このノイズ付加は科学的かつ統計的に制御されており、全体のデータ分析結果への影響を最小限に抑えつつ、個人データの特定を困難にします。
具体的には以下のようなメカニズムがあります:
- ラプラスメカニズム: データに対する統計処理の結果にラプラス分布に従ったノイズを加える手法
- ガウシアンメカニズム: ガウス分布(正規分布)に従ったノイズを加える手法
- 指数メカニズム: 特定の条件を満たすデータに対して指数関数を用いた確率分布に従って出力を選択する手法
解説:差分プライバシーの利点
差分プライバシーの最大の利点は、「匿名化」や「秘密計算」といった従来のプライバシー保護技術と比べて、大規模なデータセットに対しても適用しやすいことです。匿名化は統計量などには適用しにくく、秘密計算は計算量が膨大になるという問題がありました。差分プライバシーはデータに少量の摂動(ノイズ)を加えるだけで簡単にプライバシーを保護できるため、機械学習においても活用しやすい手法です。
Apple社の最新プライバシー保護技術 – 差分プライバシーと合成データの組み合わせ
Appleは最近、自社のAIシステム「Apple Intelligence」の精度向上とユーザープライバシー保護を両立させる画期的な技術を発表しました。この技術は差分プライバシーと合成データを組み合わせた革新的なアプローチです。
新技術の概要
Appleの新システムでは、ユーザーのデバイス上で合成データと実データを比較し、「どの合成データが実データに近いか」という情報のみをAppleに送信します。これにより、実際のユーザーデータを直接収集することなく、AIモデルの精度を向上させることが可能になりました。
解説:Private Cloud Compute
Appleは「Private Cloud Compute(プライベート・クラウド・コンピュート、PCC)」と呼ばれる独自のインフラストラクチャを開発しました。このシステムでは、ユーザーのリクエストがデバイス上で処理できない場合にのみクラウド上のシステムを利用し、その際もデータがプライバシーバブル内で完全に保護される仕組みになっています。データはリクエスト処理後に削除され、Appleを含め誰もそのデータにアクセスできません。
さらに、第三者の研究者がこのプライバシー保護機能を検証できるようにするため、Appleシリコンを搭載したサーバーで実行されるコードを調査することができる仕組みも整えられています。
連合学習 – データを共有せずに協調して学習する革新的手法
連合学習とは
連合学習(Federated Learning)は、2016年にGoogleによって提案された比較的新しい機械学習の手法です。この技術を使えば、複数の組織やデバイスが持つデータを一か所に集めることなく、協力して一つの機械学習モデルを構築することができます。
連合学習のプロセス
連合学習の基本的なプロセスは以下の通りです:
- 中央サーバーが初期モデルを作成し、各クライアント(デバイスや組織)に配布します
- 各クライアントは自分のデータでモデルをトレーニングします
- 学習結果(モデルのパラメーター)のみを中央サーバーに送り返します
- 中央サーバーは受け取ったパラメーターを集約して統合モデルを更新します
- 更新されたモデルを再びクライアントに配布し、このプロセスを繰り返します
この方法により、生データを共有することなく、全てのクライアントのデータからの知見を反映したモデルを構築できます。
解説:連合学習のメリット
連合学習の最大のメリットは、データそのものを共有することなく、複数の組織やデバイスのデータを活用できることです。これにより以下のような利点があります:
- プライバシー保護: 個人情報や機密データがサーバーに送信されないため、データ漏洩のリスクが減少します
- 法規制への対応: GDPRなどのデータ保護規制に準拠しやすくなります
- 通信量の削減: 生データではなく学習結果のみを送信するため、通信量が大幅に削減されます
- 分散データの活用: 地理的に分散したデータを効率的に活用できます
実用例:医療分野における連合学習の活用
医療分野では患者のプライバシー保護が特に重要です。連合学習はこの課題を解決しながら医療AI開発を進める有力な手段となっています。
COVID-19診断における成功事例
香港の3つの病院が連合学習を活用してCOVID-19肺異常検出のためのAIモデルを開発した事例があります。各病院は患者のCTスキャンデータを外部に共有することなく、共同でCNNベースの診断モデルを構築しました。この統合モデルは、単一施設で学習したモデルよりも高い汎化性能を発揮し、中国本土とドイツの病院のデータでも優れた診断精度を示しました。
技術の展望と課題
プライバシー保護型の機械学習技術は急速に発展していますが、いくつかの課題も残されています。
プライバシーと性能のトレードオフ
差分プライバシーでは、プライバシー保護レベルを強めると(εを小さくすると)、分析結果の精度が落ちるというトレードオフがあります。どの程度のプライバシー保護レベルが「適切」なのかという問題は、技術的な観点だけでなく、社会的・法的な側面からも検討が必要です。
連合学習の課題とその対策
連合学習は多くの利点を持つ一方で、いくつかの課題も抱えています:
- 通信コスト: パラメーターの送受信による通信コストが依然として大きい場合があります
- デバイス性能の差: 参加するデバイスの計算能力に差がある場合、効率的な学習が難しくなります
- 敵対的攻撃: 悪意あるクライアントが不正な学習結果を送信する可能性があります
これらの課題に対して、効率的な通信プロトコルの開発や、差分プライバシーとの組み合わせによるさらなるプライバシー強化など、様々な研究が進められています。
まとめ:プライバシー保護と機械学習の共存へ
差分プライバシーと連合学習は、プライバシー保護と高性能な機械学習の両立という難題に対する有望な解決策です。これらの技術は独立して使用されるだけでなく、組み合わせることでさらに強力なプライバシー保護機能を実現することができます。
今後、これらの技術はさらに洗練され、様々な分野での応用が進むことが期待されます。特に医療、金融、スマートシティなど、機密性の高いデータを扱う分野での活用が見込まれています。
プライバシーを保護しながらデータの価値を最大限に引き出す技術の発展は、「責任あるAI」の実現に向けた重要なステップであり、AIと人間社会の持続可能な共存のカギとなるでしょう。
解説:プライバシー保護技術の選び方
プライバシー保護技術は用途や状況によって使い分けることが重要です。以下に簡単なガイドラインを示します:
- 連合学習: 複数の組織やデバイス間でのデータ共有が難しい場合に適しています
- 差分プライバシー: 統計分析や機械学習の結果を公開する場合に有効です
- 秘密計算: 極めて機密性の高いデータの処理に適していますが、計算コストが高い点に注意が必要です
- 匿名化/仮名化: 基本的なプライバシー保護に役立ちますが、単独では再識別リスクがあることを認識しておく必要があります
最適な保護を実現するためには、これらの技術を組み合わせた多層的なアプローチが有効です。また、技術的な保護だけでなく、適切な組織的・管理的な対策も不可欠です。